
30 Second Summary Takeaway
RCF, or relative centrifugal force, measures the g-force a centrifuge creates at the bowl radius, while RPM measures only bowl speed. Two centrifuges running at the same RPM can produce very different RCF values if their bowl radii are different; for example, a 5 cm radius at 5,000 RPM produces about 1,400 g-force, while a 25 cm radius at the same speed produces about 7,000 g-force. For industrial centrifuge selection, RCF is the better performance measure because it describes separation force, not just rotational speed.
RCF and RPM are standard terms in the context of centrifuges. This article explains the difference between the two terms and why RCF is more relevant to centrifuges. Though the two terms are related mathematically, they are vastly different from the application's perspective.
What is RCF?
RCF stands for Relative Centrifugal Force. The force experienced by any mass (solid, liquid, or gaseous) that rotates around a fixed axis is known as the centrifugal force. RCF is this centrifugal force expressed in terms of gravity. In other words, RCF is the centrifugal force ratio to gravitational force. Therefore it is also referred to as g-force.
What is RPM?
RPM is the abbreviation for Revolutions Per Minute. It is a measure of the speed of rotation of any object. In a centrifuge, the RPM indicates the number of rotations the centrifuge bowl completes in one minute. RPM is a unitless number independent of any object's properties.
Difference Between RCF and RPM
Though RCF and RPM are units of measurement related to centrifuges, they are fundamentally different. The RCF of a centrifuge is the actual centrifugal force (or g-force) generated by the centrifuge bowl rotation.
While RPM is the bowl's rotation speed, RCF is a function of RPM and the rotating object's radius.
Why use RCF and not RPM?
As explained above, the RCF measures the centrifugal force generated by the centrifuge. This force (g-force) is directly related to the efficiency of the centrifuge. This is because the RCF indicates the centrifuge force exerted, which defines the centrifuge's separation efficiency.
The centrifuge RPM merely indicates the bowl speed but does not define the centrifugal force. In conjunction with the RPM, the rotation radius determines the centrifugal force shown by the RCF formula below.
Example of RPM vs. RCF in a Centrifuge
For example, consider two centrifuge bowls rotating at the same speed, say 5,000 RPM. One bowl has a radius of 5 cm, while the other has a radius of 25 cm.
Based on the formula, the RCF for the first bowl is 1,400 g-force. However, for the same RPM, the RCF generated by the second (larger) bowl is 7,000 g-force!
The centrifuge's separation efficiency with the 7,000g RCF will be much higher than that of the centrifuge with the 1,400g RCF.
Therefore, if the user selected the centrifuge solely based on RPM, they would make the wrong choice based on centrifuge effectiveness.
Formula to Calculate RCF from RPM
The following formula calculates a centrifuge's Relative Centrifugal Force (RCF) based on the RPM and Centrifuge Bowl Radius. The diagram also illustrates the two terms, namely RPM and bowl radius (r), in the context of the centrifuge bowl.
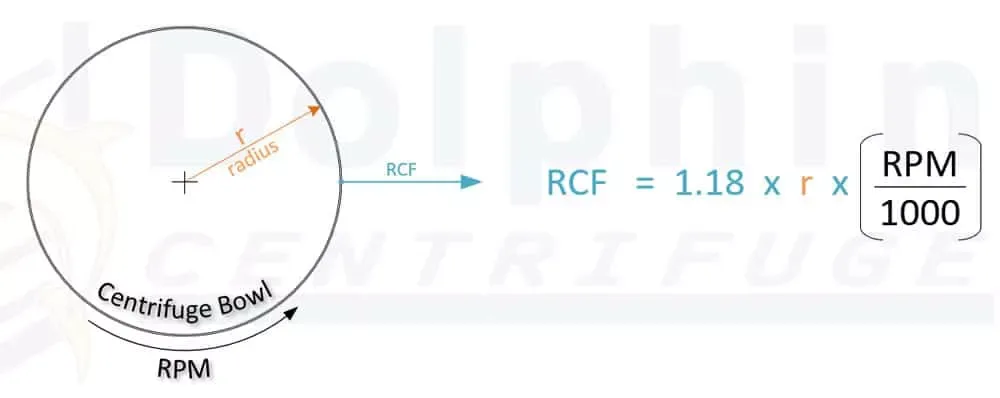
RCF = 1.118 × r × n2 × 10-5
Live RCF Calculator
Enter your centrifuge bowl radius and speed to instantly calculate RCF (g-force).
Centrifuge RCF Calculator
dolphincentrifuge.comTypical disc stack: 4-12 in; decanter: 6-20 in
Typical disc stack: 4,000-8,000 RPM
RCF Formula
2.840 × 10-5 × 8 × 6,0002
8,179
×g (RCF)
HFO, beverage clarification, coolant fine solids.
© Dolphin Centrifuge - reference only. Contact engineers for application-specific RCF requirements.
RCF in Disc Stack Centrifuge
The Relative Centrifugal Force (RCF) is the crucial factor differentiating a disc-stack centrifuge from other types of centrifuges.
An Alfa Laval disc centrifuge generates a higher centrifugal force (g-force) than simple open-bowl or decanter centrifuges. This higher force allows the disc-stack centrifuge to have higher separation efficiency.
Therefore, these centrifugal separators can separate much smaller particles than other centrifuges. They can also separate immiscible liquids with small specific gravity differentials due to their high g-force.
Summary
RCF and RPM are commonly confused and interchanged terms in the centrifuge world. These two terms are significantly different, as explained above.
For the end-user, the RCF (aka g-force) is a crucial term because it defines the effectiveness of the centrifuge. The RPM is the bowl speed indicator, but the RPM does not convey any useful information for the application or the process.
Related Articles
How to optimize g-force, throughput, and separation quality.
Disc Centrifuge DisadvantagesAn honest assessment of disc stack centrifuge limitations.
Bad Separation Troubleshooting6 causes of poor disc centrifuge separation and how to fix them.
Disc Stack Centrifuge FAQ101 frequently asked questions about disc stack centrifuges.
Disc Stack Centrifuge Overview
Types, models, and capacity
Need RCF Calculations for Your Application?
Dolphin Centrifuge engineers calculate required g-force for your specific fluid, particle size, and separation target - then recommend the right centrifuge model.